Graphql
Introduction
This document provides some general information about the GraphQL API of the IdentityHub
Learning by Doing
First of all the IdentityHub provides a playground which helps to debug GraphQL queries and implementations. You can explore the documentation, try out every query and get detailed insight on the IdentityHub API.
You can access the playground by opening the IdentityHub route /-/playground in your browser.
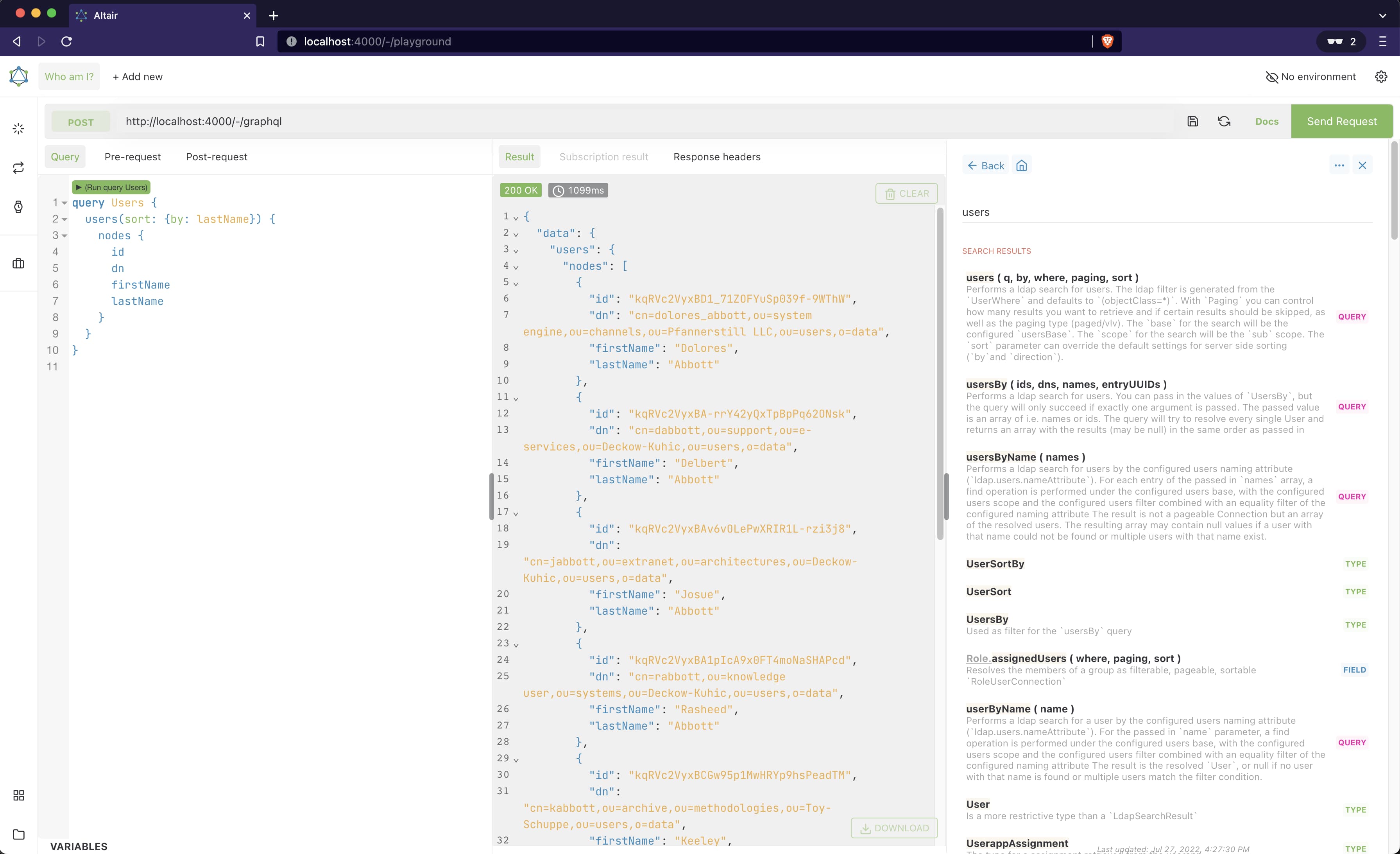
Because of the detailed information you can get about the API, the playground is disabled in production by default. To activate the playground also in production configure:
[graphql]
exposePlayground = true
The playground uses an IntrospectionQuery (the __schema query) to provide auto-completion, validation, and API documentation. This query still works, even if the playground is disabled. To disable the query itself as well, please see the corresponding
customization section.
How to filter
Almost every query provides the possibility to filter the results. The way how the filtering works differs a little bit between the different connected APIs (LDAP, Userapp, Alfresco, etc.), but in most cases you can pass the where parameter to the query which provides you with a certain amount of possibilities based on the type of the query. Below are some simple examples on how the filtering works for different queries.
Find all users (LDAP) that have been created after a certain date and whose firstName starts with the letter M:
query SearchUsers {
users(
where: { createTimestamp: { lte: "2018-12-10T11:25:16Z" }, givenName: { startsWith: "M" } }
) {
nodes {
firstName
lastName
}
}
}
Find all tasks (Userapp) that the logged in user is assigned to and that contain a certain string in i.e. the name or description:
query SearchTasks {
viewer {
tasks(where: { q: "some string", assignee: me }) {
nodes {
id
processName
}
}
}
}
Find all tasks (Activiti) that the logged in user is assigned to and that contain a certain string in i.e. the name or description:
query SearchTasks {
viewer {
tasks(where: { q: "some string", assignee: me }) {
nodes {
id
processName
}
}
}
}
Find all processes (Alfresco Activiti) that are already completed and started by a certain user:
query SearchProcesses {
alfrescoWorkflowProcesses(
where: { status: { eq: completed }, startUserId: { eq: "some user id" } }
) {
nodes {
id
name
priority
}
}
}
Results - single or connection
Basically there are two different types of queries. Those that return a single result and those that may return more than one result. In general you can distinguish them by there name (user - users, task - tasks, etc.)
Single results
You can use queries like i.e. user or group to filter and find exactly one result. For example find a user by the ID:
query FindUserByID {
user(where: { id: { eq: "xxx" } }) {
id
dn
}
}
As the id should be unique, you can expect to find exactly one result (or none if no user found). If you use a filter that matches multiple users, the query will return null. The same goes for all other single queries.
Instead of the here shown where filter, we recommend the shorthand by filter that can be used as LDAP filters when matching with eq (equals). Please see the
LDAP section for a more detailed explanation.
Connections
The queries that may return multiple results, like i.e. users, groups, tasks, alfrescoWorkflowProcesses, etc. will return a so called Connection. The Connections the IdentityHub returns are inspired by the
Relay Cursor Connection specification.
A Connection consists of a pageInfo field, a field estimatedSize, as well as the fields nodes and edges. those fields are explained in detail below.
pageInfo
The pageInfo field is, as the name may suggest, used to store information about paging. It consists of the fields hasNextPage, hasPreviousPage, startCursor and endCursor. hasNextPage and hasPreviousPage are self explanatory. The cursor fields tell you what are the first an last cursors in your received result.
estimatedSize
This field is an additional field added by the IdentityHub and returns the amount of results that match your filter even if you may not receive all of them at once. This field may be null if the proxied API does not provide this information.
nodes
The nodes field contains an array of the actual results.
edges
The edges field is like the nodes field an array but adds a cursor information. Every edge consists of a cursor field and the node field, which contains the actual data.
Paging
To actually use connections you have to use the paging parameter in your queries. Otherwise, you always will only receive the first 10 (default limit value) results. Every query that returns a Connection takes a parameter paging, which consists of the input parameters after, before, first, last, and limit. With those, you can control which part of the result set you want to receive. For example, you can tell the IdentiyHub to give you the first 20 results after a given cursor or the last 3 results before a cursor. limit is just a shortcut if you want to increase or decrease the amount of fetched results.
For example with a client application you are querying users like that,
query SearchUsers {
users(paging: { first: 3, after: null }) {
pageInfo {
hasNextPage
endCursor
}
nodes {
id
dn
}
}
}
you will receive the first 3 users matching the filter (or unfiltered if no filter is present). You app could now check if hasNextPage is true, and if so, you can request the next 3 results by using the value from pageInfo.endCursor as after parameter:
query SearchUsers {
users(paging: { first: 3, after: "insert the value from [pageInfo.endCursor]" }) {
pageInfo {
hasNextPage
endCursor
}
nodes {
id
dn
}
}
}
For backwards paging you may want to use last and before parameters.